

1. Executive Summary
Realtime object detection has undergone a generational leap with the release of YOLO26 in September 2025. By eliminating Non Maximum Suppression(NMS) and Distribution Focal Loss(DFL), two components that have constrained the YOLO family since its inception, YOLO26 achieves up to 43 % faster CPU inference than its predecessor while exceeding detection accuracy across all model scales. These architectural simplifications are not merely academic but they directly address the most persistent pain points in deploying object detection models to production surveillance systems, where latency, export compatibility, and quantization robustness, determine whether a model is production ready or remains a research artifact.
This white paper provides a comprehensive technical analysis of the YOLO26’s architectural innovations to a fully operational, production ready surveillance pipeline. It covers the model’s four key innovations, NMS-free inference, DFL removal, ProgLoss with STAL for small object detection, and the MuSGD optimizer, and evaluates their impact through official benchmarks on COCO val2017 and NVIDIA Jetson Orin edge platforms. Beyond the benchmarks, this paper examines the surveillance stack: hardware accelerated video decode, batched preprocessing, multi object tracking algorithms (ByteTrack, BoTSORT, DeepSORT), zone based analytics, event generation, metadata brokering, and the continuous improvement loop from edge inference to cloud training.
2. The evolution over time
The YOLO (You Only Look Once) family has defined the standard for realtime object detection since its introduction in 2016. Understanding YOLO26’s innovations requires context about the architectural decisions and trade offs that accumulated through a decade of iterative development.
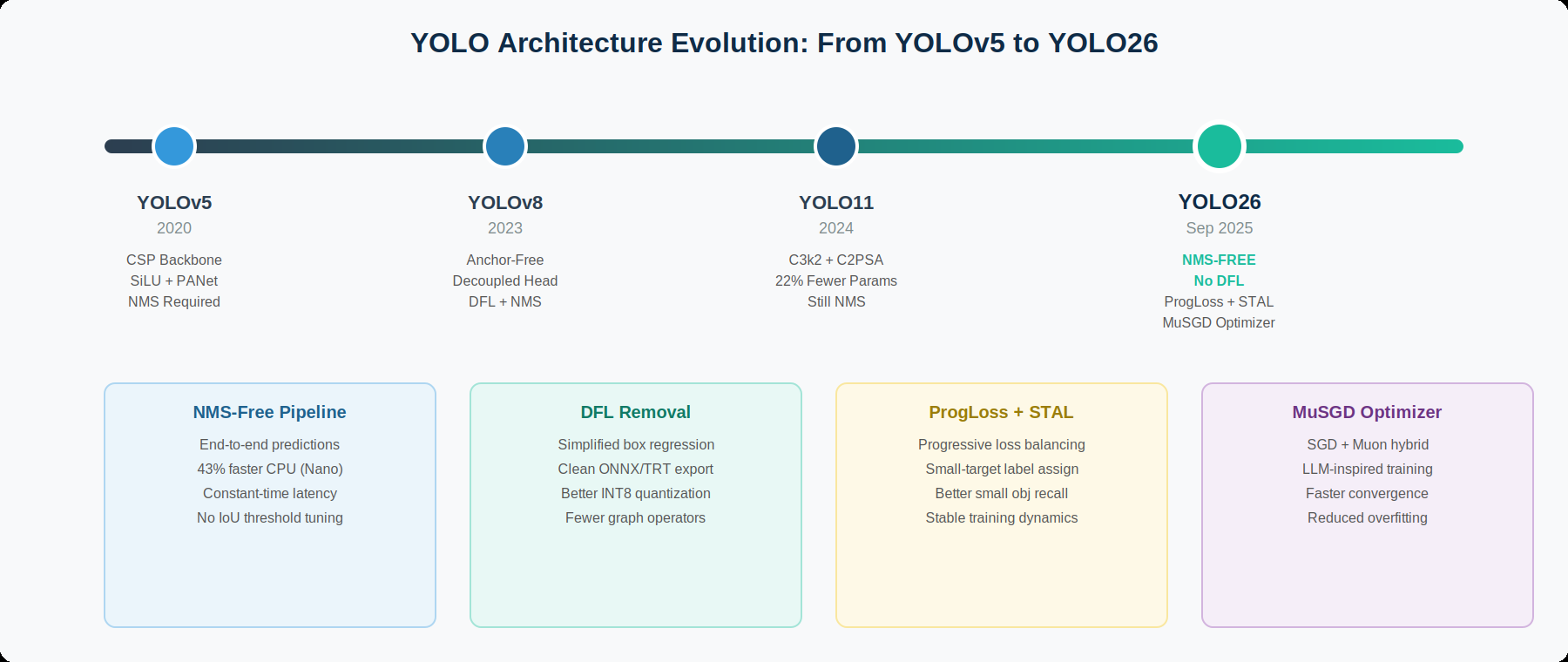
2a. The Ultralytics Lineage
Ultralytics has maintained the production ready YOLO line since YOLOv5 (2020), which introduced the modular PyTorch implementation with depth and width scaling. YOLOv8 (2023) advanced the architecture with a decoupled detection head, anchor free predictions, and CIoU loss, becoming the most widely deployed YOLO variant in industry. YOLO11 (2024) introduced compact C3K2 bottleneck blocks and C2PSA attention modules, requiring 22% fewer parameters than equivalent YOLOv8 variants while maintaining competitive accuracy.
In parallel, community driven variants such as YOLOv9 through to YOLOv13, explored attention mechanisms, hypergraph feature aggregation, and transformer inspired designs. While these variants often achieved strong benchmark scores, they consistently retained NMS and DFL dependencies that complicated edge deployment. The limitations of these components motivated the rearchitecture of YOLO, that became YOLO26.
2b. The Transformer Challenge: RF-DETR and RT-DETR
The emergence of transformer based realtime detectors, particularly RT-DETR and RF-DETR, challenged YOLO’s dominance by demonstrating NMS-free detection with competitive accuracy. RF-DETR, released by Roboflow in March 2025, leverages a DINOv2 backbone to achieve 53% mAP on COCO, while running at 3.52ms on a T4 GPU, outperforming YOLO11X in both accuracy and speed. These transformer detectors demonstrated that full stack prediction without post processing was not only feasible but advantageous.
However, transformer based detectors carry trade offs for edge deployment. Dynamic attention mechanisms create export difficulties for TensorRT and TFLite, memory requirements increase drastically and additionally with input resolution & quantization to INT8, often leads to degraded accuracy when compared to convolutional architectures. YOLO26’s response was to adopt the end to end principle while retaining the convolutional backbone that makes YOLO edge friendly.
3. YOLO26: Architecture Deep Dive
YOLO26 is built on three guiding principles, Simplicity, Efficiency, and Innovation, that collectively represent the most significant architectural change in the Ultralytics lineage. This section examines each innovation in technical detail.
3a. NMS-Free Inference
Non Maximum Suppression(NMS) has been the single most problematic component in production YOLO deployments. NMS is sequential & it iterates through detections sorted by confidence, computing IoU, and suppressing overlapping predictions. This sequential nature creates two problems. First, latency scales with the number of detections, such as, in crowded scenes with hundreds of initial predictions, NMS in itself, could consume more time than the neural network inference. Second, NMS requires manual threshold tuning (IoU threshold, confidence threshold) that is very scene dependent, creating maintenance restrictions, when deployed across diverse sites.
YOLO26 eliminates NMS by redesigning the prediction head to use one to one label assignment during training. Instead of producing many overlapping predictions, that require post processing suppression, YOLO26’s head learns to output a compact, non redundant set of detections, directly. The result is a constant time inference pipeline, where latency is independent of scene complexity. The nano variant, yields up to 43% faster CPU inference compared to YOLO11-N, reducing ONNX CPU latency from approximately 56.1ms to 38.9ms. On GPU, the improvement is smaller but significant. T4 TensorRT latency drops from approximately 1.7ms to 1.55ms.
3b. Distribution Focal Loss Removal
Distribution Focal Loss was introduced in YOLOv8, to improve bounding box localization by predicting probability distributions over coordinate offsets, created persistent export and deployment issues. The distributional representation required specialized operators that were not uniformly supported across inference runtimes. This caused performance degradation when targeting TensorRT, CoreML, TFLite, and OpenVINO. DFL also complicated INT8 quantization because the distributional softmax layer was sensitive to reduced precision.
YOLO26 replaces DFL with a lighter, hardware friendly parameterization of bounding boxes, that produces direct coordinate predictions. This simplification reduces the ONNX graph complexity, eliminates runtime specific workarounds, during model export and enables cleaner quantization to FP16 and INT8 with the lowest accuracy loss. The removal of DFL is one of the key reasons YOLO26 achieves consistent accuracy between FP32 and FP16 precision. This is critical for edge compute deployments where FP16 or INT8 execution is standard.
3c. ProgLoss and STAL: Small Object Excellence
Surveillance systems must detect objects across a wide range of scales. From full frame objects near the camera to pixel scale targets at range. YOLO26 introduces two training innovations specifically targeting this challenge:
- Progressive Loss Balancing(ProgLoss) dynamically adjusts the relative weights of classification, localization and auxiliary loss components throughout training, preventing the model from over optimizing for easy large object detections, at the expense of difficult small objects.
- Small Target Aware Label Assignment(STAL) adjusts the label assignment strategy to ensure that small, partially occluded or low contrast objects receive adequate supervisory signal during training.
All together, these innovations measurably improve recall for small objects. Especially, the category that matters most in surveillance scenarios, where threats may appear as distant, partially obscured figures.
3d. MuSGD Optimizer
YOLO26 adopts MuSGD, a hybrid optimizer that combines the generalization properties of stochastic gradient descent with curvature aware momentum updates, inspired by optimizers used in large language AI model training. MuSGD shortens time to quality during training and mitigates late epoch instability, that can affect the final model accuracy. For production teams running continuous retraining cycles, MuSGD’s faster convergence translates directly to reduced GPU hours required per training, thus saving operational costs.
4. Performance Benchmarks
YOLO26’s performance was extensively benchmarked on the MS COCO val2017 dataset at 640px image input resolution, with latency measurements on both CPU (ONNX runtime) and NVIDIA T4 AI GPU (TensorRT10 FP16).
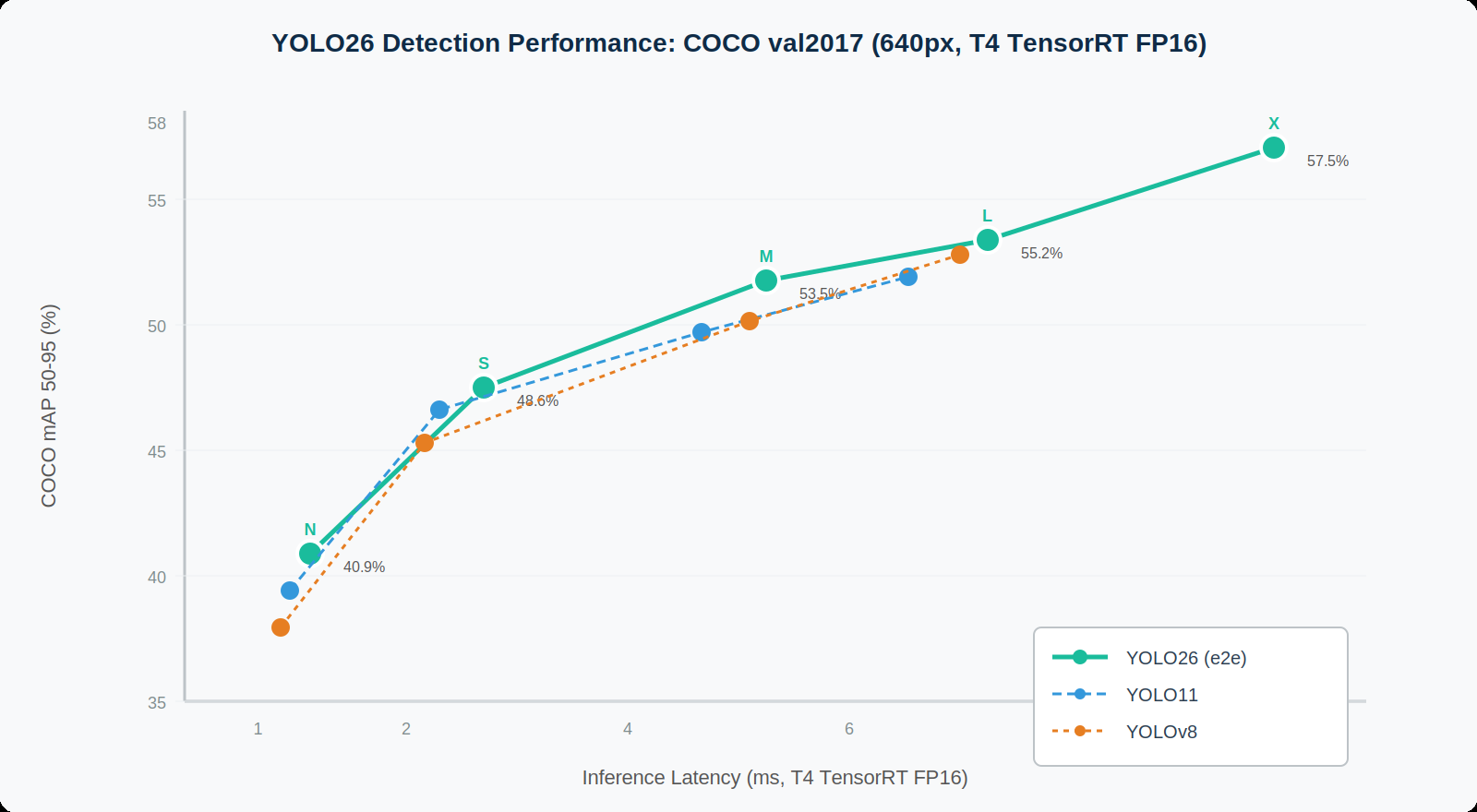
4a. Official COCO Detection Results
| Model | mAP 50-95 | mAP e2e | CPU ONNX (ms) | T4 TRT (ms) | Params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO26-N | 40.9% | 40.1% | 38.9 | 1.7 | 2.4 | 5.4 |
| YOLO26-S | 48.6% | 47.8% | 87.2 | 2.9 | 9.2 | 24.0 |
| YOLO26-M | 53.5% | 52.8% | 220.0 | 5.5 | 19.5 | 68.4 |
| YOLO26-L | 55.2% | 54.5% | 286.2 | 7.8 | 23.5 | 82.9 |
| YOLO26-X | 57.5% | 56.9% | 525.8 | 11.8 | 55.7 | 193.9 |
Source: Ultralytics official benchmarks. CPU speeds measured with ONNX export; GPU speeds measured with TensorRT export. mAP e2e reflects end to end accuracy without separate NMS post processing.
4b. Cross Generation Comparison
| Model | mAP 50-95 | CPU (ms) | T4 TRT (ms) | Params (M) |
|---|---|---|---|---|
| YOLO26-N | 40.9% | 38.9 | 1.7 | 2.4 |
| YOLO11-N | 39.5% | 56.1 | 1.55 | 2.6 |
| YOLOv8-N | 37.3% | 80.4 | 1.47 | 3.2 |
| YOLOv5u-N | 34.3% | 73.6 | N/A | 2.6 |
| YOLO26-S | 48.6% | 87.2 | 2.9 | 9.2 |
| YOLO11-S | 47.0% | 90.0 | 2.46 | 9.4 |
| YOLOv8-S | 44.9% | 128.4 | 2.33 | 11.2 |
| YOLO26-M | 53.5% | 220.0 | 5.5 | 19.5 |
| YOLO11-M | 50.3% | 171.0 | 4.70 | 20.1 |
| YOLOv8-M | 50.5% | 197.5 | 5.09 | 25.9 |
| RF-DETR-S | 53.0% | N/A | 3.52 | 29.0 |
| RF-DETR-M | 55.0% | N/A | ~5.0 | 54.0 |
| YOLOv12-N | 40.6% | N/A | 1.64 | 2.6 |
| YOLOv12-L | 53.2% | N/A | 6.14 | 26.4 |
Key findings: YOLO26-N achieves 40.9% mAP with 43% faster CPU inference than YOLO11-N at comparable GPU latency. YOLO26-S matches RF-DETR-S accuracy but with one third the parameter count and broader edge compatibility. YOLO26-M at 53.5% mAP exceeds both YOLO11-M and YOLOv8-M, while maintaining cleaner export characteristics.
5. Production Surveillance Pipeline Architecture
A production ready surveillance pipeline extends far beyond the detection model. It includes video capture, hardware accelerated decoding, batched preprocessing, multi model inference, object tracking, zone analytics, event generation, and telemetry, all orchestrated to maintain real time throughput across multiple concurrent camera streams.
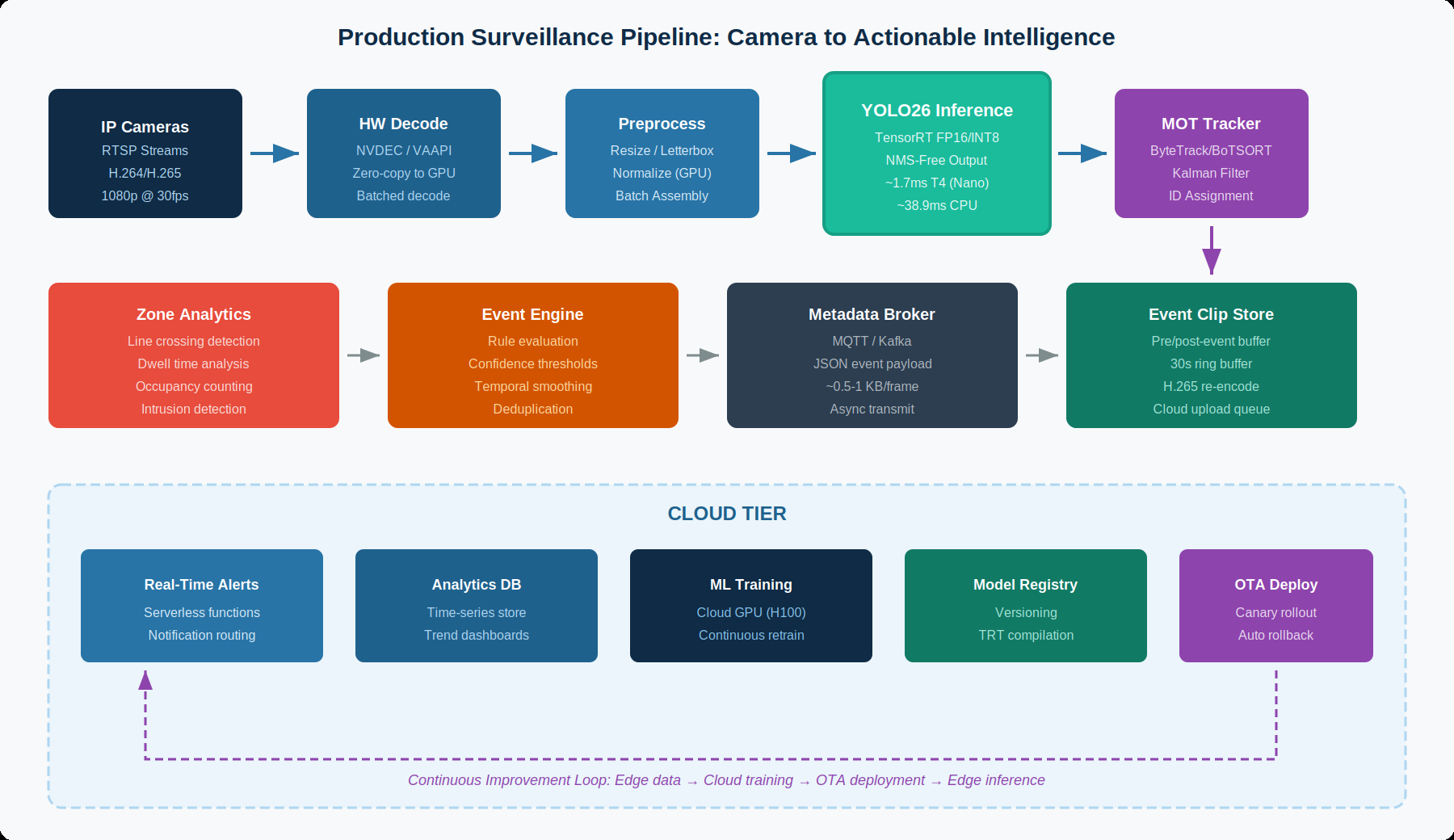
5a. Video Capture and Hardware Decode
IP cameras deliver H.264 or H.265 encoded video over RTSP at resolutions from 720p to 4K. The first critical optimization in the pipeline is hardware accelerated video decoding. On NVIDIA platforms, NVDEC can decode multiple simultaneous streams without consuming GPU compute cycles, enabling the GPU to focus entirely on inference. A single Jetson AGX Orin, can decode up to 32 concurrent 1080p H.265 streams through NVDEC, while simultaneously running detection models on the GPU.
NVIDIA’s DeepStream SDK manages this pipeline through GStreamer plugins, that handle the flow from RTSP source to inference output. The nvv4l2decoder plugin performs hardware decode, nvstreammux batches decoded frames, from multiple cameras into a single tensor, and nvinfer executes TensorRT-optimized models on the batched input. This architecture achieves near zero frame copies between decode and inference. Then the decoded NV12 frames are converted to RGB and resized directly on the GPU with no CPU.
5b. Batched Inference with YOLO26
YOLO26’s NMS-free architecture provides a unique advantage for batched surveillance inference. In traditional YOLO pipelines, NMS must be applied per frame after batched inference, reintroducing sequential processing, that partially negates the parallelism gains of batching. YOLO26’s direct, non redundant output, eliminates this bottleneck. The model produces final detections for all frames, in the batch simultaneously.
For a production deployed example, consider a 16 camera deployment on a Jetson AGX Orin running YOLO26-S (48.6% mAP). At 640px input with TensorRT FP16 optimization, each frame requires approximately 2.9ms of inference on a T4-class GPU. Batching 16 frames together amortizes fixed overhead, achieving effective per frame latency of approximately 1 to 1.5ms. At 5 frames per second per camera, the total inference load is 80 frames per second, which gives enough room for tracking and analytics.
5c. Multi Model Cascade Architecture
Production surveillance systems rarely rely on a single detection model. A normal architecture commonly uses a cascade of models with increasing specificity:
- First stage: A fast, lightweight detector(YOLO26-N or YOLO26-S) running on every frame to detect persons, vehicles and objects of interest.
- Second stage (triggered): When the first stage detects a relevant object, it triggers secondary models that run on cropped regions of interest:
- A face detection model for identity relevant scenarios
- An attribute classifier for clothing color, bag detection or uniform recognition
- A pose estimation model(YOLO26-pose) for behavior analysis such as fall detection or aggressive posture recognition
This cascade architecture provides additional latency headroom, for dramatically improved actionable intelligence. The first stage detector runs at full frame rate across all cameras, while secondary models execute only on triggered crops, which is typically 1 to 5% of the total frames. YOLO26’s multitask support (detection, segmentation, pose estimation and classification within the same model family) simplifies this cascade by enabling a single framework, training pipeline, and deployment toolchain across all stages.
6. Multi Object Tracking for Surveillance
Object detection identifies what is in each frame. Object tracking maintains identity across the frames. In surveillance, tracking transforms isolated detections into trajectories, dwell times, path histories, and behavioral patterns. The choice of tracking algorithm profoundly impacts system performance, with trade offs between computational cost, ID consistency, and occlusion handling.
6a. Tracking Algorithm Comparison
| Algorithm | Approach | Compute Cost | ID Switches | Occlusion Handling | Best For |
|---|---|---|---|---|---|
| ByteTrack | Motion only (IoU) | Very low | Moderate | Good (uses low conf) | High-FPS, budget HW |
| BoTSORT | Motion + ReID | Medium | Low | Very good | Balanced surveillance |
| DeepSORT | Motion + ReID | High | Low | Good | High acc, GPU available |
| OC-SORT | Motion only | Very low | Low moderate | Good | Nonlinear motion |
| StrongSORT | Motion + ReID + EMA | High | Very low | Excellent | Max accuracy, server |
| NvDCF (DeepStream) | DCF + ReID | Medium | Low | Very good | NVIDIA pipelines |
6b. ByteTrack: The Edge Optimized Tracker
ByteTrack, published at ECCV 2022, introduced a simple but highly effective innovation. Tracking low confidence detections alongside high confidence ones. Traditional trackers discard detections below a confidence threshold, losing track of partially occluded objects. ByteTrack performs a two stage association. First matching high confidence detections to existing tracks using IoU similarity and the Hungarian algorithm and then matching the remaining low confidence detections to unmatched tracks. This second pass recovers objects that are temporarily occluded or moving through challenging lighting conditions.
For YOLO26 deployments on constrained edge hardware, ByteTrack is the recommended default tracker. It adds sub ms computational overhead (less than 0.1ms per frame), requires no GPU accelerated ReID model, and integrates natively with the Ultralytics framework via a single configuration parameter. The combination of YOLO26’s NMS-free output and ByteTrack’s hierarchical association creates a remarkably clean pipeline, from detection to tracking with no post processing gaps.
6c. BoTSORT: Balanced Production Tracker
BoTSORT (Bag of Tricks for SORT) extends ByteTrack with three improvements that matter for production surveillance. Kalman filter that estimates width and height directly, camera motion compensation that handles PTZ camera movement, and an optional ReID (reidentification) network that uses appearance features for more robust identity matching. The ReID component adds 2 to 5ms of latency per frame depending on the number of tracked objects and the ReID model size, but significantly reduces ID switches in scenarios where objects leave and reenter the frame or pass behind occluding structures.
BoTSORT is the recommended tracker for deployments where identity consistency is critical, such as a retail customer journey analysis, warehouse worker tracking and any scenario where the same individual must be tracked across extended time periods. Both ByteTrack and BoTSORT are natively supported in the Ultralytics YOLO framework and can be selected via YAML configuration files.
6d. Multi Camera Tracking
Single camera tracking maintains identity within one video stream. Multi camera tracking (MCT) extends identity across cameras covering a shared space. NVIDIA’s DeepStream SDK provides a Multi-View 3D Tracking (MV3DT) framework, introduced in DeepStream 8.0, that delivers distributed realtime tracking across calibrated camera networks. The system uses camera calibration data for geometric reasoning, maintains global IDs across camera handovers and supports scaled deployments, where each camera’s perception pipeline can run on different edge compute devices while communicating with Kafka message broker.
Multi camera tracking enables powerful surveillance capabilities including cross camera trajectory analysis(tracking a person’s path through an entire facility), dwell time accumulation across multiple zones and anomaly detection based on unusual movement patterns that span camera boundaries. The NVIDIA Metropolis Blueprint for multi camera tracking provides a reference architecture that integrates DeepStream perception, Kafka messaging and Elasticsearch for persistent storage and search.
7. Edge Deployment Optimization
The gap between research accuracy and production performance is where many object detection projects fail. YOLO26’s architectural simplifications significantly narrow this gap, but systematic optimization remains essential for achieving target throughput on edge hardware.
7a. TensorRT Optimization Pipeline
The standard deployment path for YOLO26 on NVIDIA hardware follows a three stage optimization pipeline:
- ONNX Export: The PyTorch model is exported to ONNX format using
torch.onnx.export, producing a framework agnostic graph, that captures all operations including YOLO26’s NMS-free prediction. And as YOLO26 removes DFL, the ONNX graph contains no distributional softmax operators, that historically caused export issues, resulting in a clean graph, that validates across all target runtimes. - TensorRT Compile: The ONNX model is compiled to a TensorRT engine using
trtexecoor the Ultralytics export pipeline. TensorRT applies layered fusion(combining convolution, batch normalization, and activation into single kernels), kernel auto tuning(selecting the fastest CUDA kernel for each operation on the target GPU microarchitecture) and optional INT8 calibration using a representative dataset of 500 to 1,000 images, from the deployment domain. TensorRT compilation is hardware specific. An engine compiled for Jetson Orin Nano will not run on Jetson AGX Orin or datacenter GPUs. - Deployment: The compiled engine is deployed through DeepStream’s
nvinferplugin or a custom TensorRT inference application. Key deployment parameters include batch size, matching the number of camera streams, workspace memory allocation and dynamic shape support, if cameras operate at different resolutions.
7b. INT8 Quantization Results
INT8 quantization is the most impactful optimization for edge inference, reducing model size by approximately 4x and increasing throughput by 2 to 3x, compared to FP32. YOLO26’s clean architecture free of DFL’s distributional softmax and NMS’s threshold sensitive operations, makes it exceptionally quantization friendly. With proper calibration using 500 to 1,000 representative images, YOLO26 models typically lose less than 1% age point of mAP when quantized from FP32 to INT8, compared to 1.5 to 3.0% of loss observed with YOLOv8 and YOLO11 models, that retain DFL.
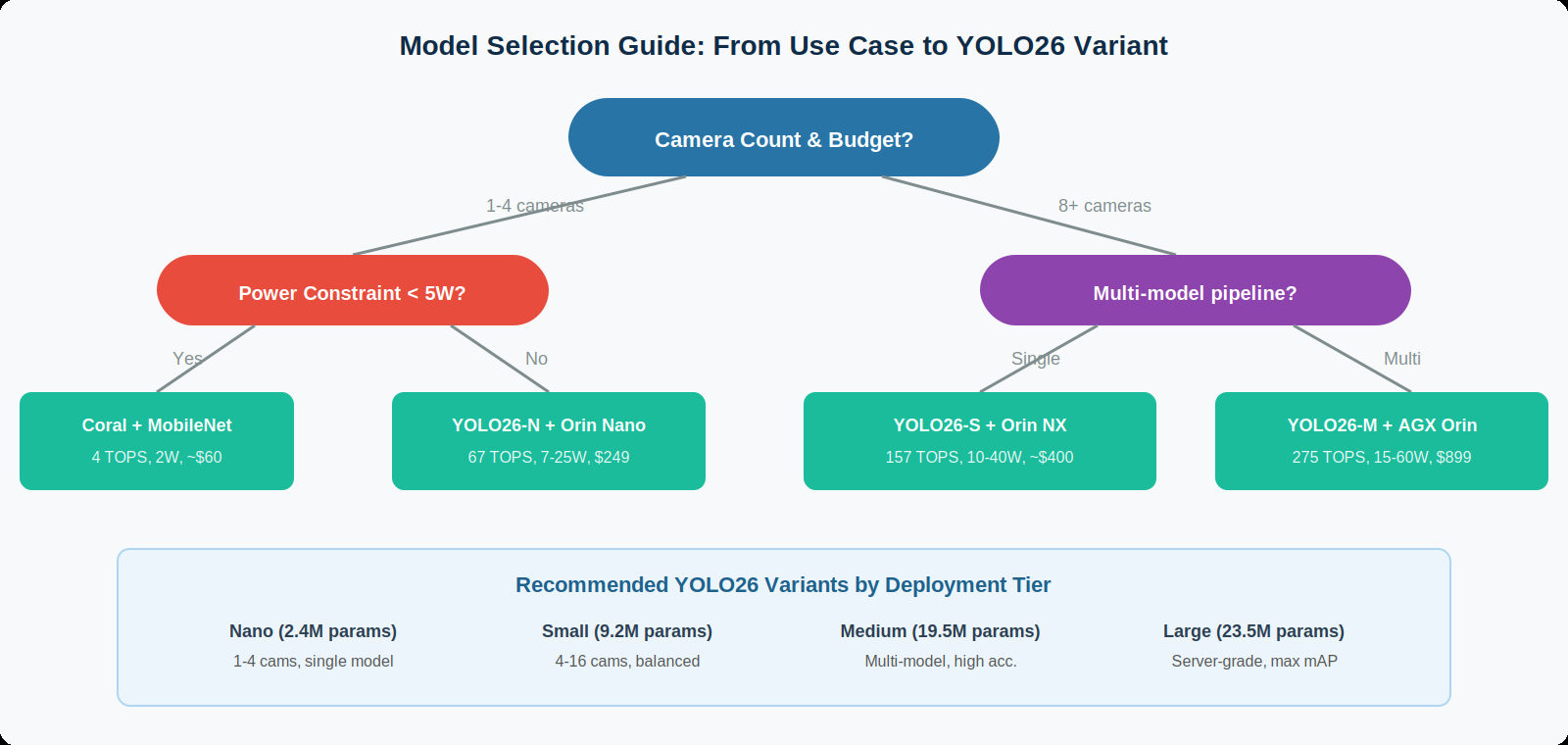
7c. Hardware Sizing Guidelines
| Deployment Scale | YOLO26 Variant | Edge Hardware | FPS per Camera | Total Streams |
|---|---|---|---|---|
| Single camera, battery | Nano (INT8) | Coral Edge TPU | ~10 FPS | 1 |
| 1–4 cameras, compact | Nano (FP16) | Jetson Orin Nano | 15–25 FPS | 4 |
| 4–16 cameras, mid tier | Small (FP16) | Jetson Orin NX | 10–20 FPS | 16 |
| 8–32 cameras, high perf | Small/Med (FP16) | Jetson AGX Orin | 10–15 FPS | 32 |
| 32–100 cameras, server | Medium (FP16) | T4/L4 edge server | 15–30 FPS | 64–100 |
| 100+ cameras, rack | Med/Large (FP16) | A30/A100 server | 20–30 FPS | 100+ |
8. Zone Analytics and Event Generation
Raw detections and tracks become actionable intelligence through zone analytics, the software layer that applies spatial rules, temporal filters, and business logic to transform bounding boxes into meaningful events.
8a. Core Analytics Features
Line Crossing: A virtual tripwire defined by two endpoints in image coordinates. When a tracked object’s centroid crosses the line, an event is generated recording the object class, track ID, crossing direction and timestamp. Common applications include entrance/exit counting, direction of travel analysis, and perimeter monitoring.

Zone Occupancy: A polygon defined region where tracked objects are counted. Objects whose bounding box centroid falls within the polygon increment the zone counter. Objects leaving decrement it. Occupancy thresholds trigger events. For example, alerting when a restricted area exceeds its maximum permitted occupancy or when a critical zone has been empty for an unusual duration.

Dwell Time: The duration a tracked object remains within a defined zone. Dwell time analysis identifies loitering behavior in security applications, customer engagement in retail and workflow bottlenecks in industrial settings. A typical dwell time alert triggers after a configurable threshold(30 to 60 seconds), with a deduplication window to prevent repeated alerts for the same individual.
Intrusion Detection: A zone based rule that generates an immediate high priority alert, when any object of a specified class (typically "person") is detected within a restricted zone during specified time windows. Intrusion detection layers temporal scheduling(active only during non business hours), with spatial constraints(specific restricted areas) and class filtering.

8b. False Positive Reduction
Production surveillance systems face relentless pressure to minimize false positive alerts. Alert fatigue(when operators receive so many spurious alerts that they begin ignoring genuine ones), is the single most common failure mode in deployed surveillance systems. YOLO26’s improved small object detection via STAL reduces one source of false positives(misclassified background artifacts), but the analytics layer must apply additional filtering.:
- Temporal smoothing requires that a detection persist for a minimum number of consecutive frames(typically 60 to 80 frames) before generating an alert, filtering out single frame hallucinations.
- Confidence thresholds are tuned per class and per zone, based on empirical false positive rates for each deployment site.
- Minimum and maximum object size filters reject detections that are implausible, given the camera’s field of view and mounting height.
- Track length filters require a minimum trajectory length before events are generated, filtering out stationary false positives caused by lighting changes or reflections.
Together, these filters can reduce false positive rates by 90 to 95% compared to raw detector output, with minimal impact on true positive recall.
9. NVIDIA DeepStream Integration
NVIDIA DeepStream SDK provides the production grade pipeline framework ,that connects YOLO26 inference to the complete surveillance stack. DeepStream is a GStreamer based streaming analytics toolkit with 40+ hardware accelerated plugins and 30+ sample applications, purpose built for video insight workflow.
9a. Pipeline Configuration
A DeepStream YOLO26 surveillance pipeline consists of the following GStreamer elements chained in sequence:
nvurisrcbin: RTSP stream ingestion with automatic reconnectionnvstreammux: Batching multiple camera streams into a single GPU tensornvinfer: TensorRT optimized YOLO26 inferencenvtracker: Real time multi object tracking using NvDCF or ByteTrack style algorithmsnvdsanalytics: Zone based line crossing and occupancy countingnvmsgconv: Metadata serialization to JSON or protobuf formatnvmsgbroker: Transmitting events to Kafka, MQTT or AMQP message brokers
DeepStream’s Inference Builder, introduced in recent SDK versions, simplifies this configuration to a declarative YAML definition, where developers specify model paths, camera URLs, analytics zones and message broker endpoints without writing GStreamer pipeline code. This dramatically reduces the engineering effort required to go from a trained YOLO26 model to a deployed multi camera surveillance system.
9b. Performance Optimization
Key DeepStream optimizations for YOLO26 deployments include:
- Enabling the hardware video decoder for all streams to keep GPU compute available for inference.
- Using batch sizes equal to the number of cameras to maximize GPU utilization.
- Enabling asynchronous metadata output, so that message broker latency does not block the inference pipeline.
- Configuring the tracker interval to reduce per frame tracking cost by applying the tracker on every frame but the full ReID model only every N frames.
10. The Continuous Improvement Loop
A deployed surveillance system is not a static installation. It is a living system that adapts to changing environments, new object classes and evolving accuracy requirements. The continuous improvement loop connects edge inference to cloud training through a feedback mechanism driven by model uncertainty.
10a. Active Learning at the Edge
Edge devices implement active learning by monitoring detection confidence distributions, in real time. When YOLO26 produces detections with confidence scores between configurable thresholds, the associated video frames are flagged as high value training candidates. These uncertain predictions is key to the model’s knowledge. Objects that the model can partially recognize but is not confident about. Collecting these edge cases for annotation and retraining yields higher improvement per training sample, when compared to random frame selection.
The edge device maintains a local buffer of flagged frames and metadata, uploading them to cloud storage during off peak hours or via scheduled batch transfers. A typical 100 camera deployment, generates 50 to 200 high value training samples per day, accumulating sufficient data for a retraining cycle every 2 to 4 weeks. Each retraining cycle improves the model on the scenarios where the model previously struggled, creating a cycle of increasing accuracy, that is specific to each deployment’s unique environmental conditions.
10b. OTA Model Deployment with YOLO26
YOLO26’s consistent accuracy between FP32 and FP16 precision simplifies the OTA deployment pipeline. Trained models are exported to ONNX, compiled to TensorRT engines for each target hardware variant and distributed through the edge runtime(IoT Greengrass, AI Edge, or Kubernetes). YOLO26’s clean ONNX export means that model compilation can be automated without the manual intervention, often required for previous YOLO versions. The NMS-free architecture also eliminates the need to tune post processing parameters per deployment site, removing a common source of deployment time regressions.
11. Future Prospects
11a. YOLO26 with Vision Language AI Models
The convergence of YOLO class detectors with vision language AI models(VLMs), opens a new opportunity for surveillance. Instead of pre defining object classes at training time, operators could ask questions in natural language such as "show me anyone carrying a large package near the east entrance after midnight”, and receive results from a system that combines YOLO26’s spatial detection with AI VLM reasoning. NVIDIA’s Metropolis Blueprint for Video Search and Summarization (VSS) provides an early reference architecture for this capability, using DeepStream for real time detection and generative AI for natural language interaction with video archives.
11b. Edge Native Generative AI for Alert Context
Generative AI is beginning to enhance surveillance workflows by automatically producing human readable incident summaries from structured detection metadata. A generative AI model synthesizes context such as:
"At 14:32, a person entered the restricted loading dock through the south gate, remained for 47 seconds near rack 12, then exited northward. No safety vest detected. Similar pattern observed 3 times this week."
As edge hardware like Jetson AGX Thor(128 GB memory, 2,070 TOPS) becomes available, these generative summarization capabilities can run entirely at the edge, providing contextual intelligence without cloud dependency.
12. Conclusion
YOLO26 represents a significant moment in the evolution of real time object detection. It not only achieves dramatically higher accuracy than its predecessors but also eliminates the architectural compromises that have historically prevented YOLO models from achieving their full potential in production edge AI camera deployments. By removing NMS and DFL, YOLO26 delivers a model that exports cleanly to inference runtime, quantizes to INT8 with minimal accuracy loss, achieves constant time latency regardless of scene complexity and eliminates the deployment time threshold tuning that has been a persistent source of production deployment blocker.
When combined with production grade tracking algorithms(ByteTrack for resource efficiency, BoTSORT for identity consistency), zone analytics for actionable intelligence and NVIDIA DeepStream for hardware accelerated pipeline orchestration, YOLO26 forms the foundation of surveillance systems that can process 16 to 32 camera streams on a single Jetson AGX Orin, 100+ streams on a T4 edge server and thousands of streams across distributed deployments managed by Kubernetes native orchestration.
The active learning at the edge, cloud based retraining and automated OTA deployment, ensures that deployed systems improve over time for the environment the cameras are deployed. YOLO26’s clean export characteristics and NMS-free architecture make this loop more reliable and less maintenance intensive, than previous generations, reducing the total cost of ownership for organizations operating large scale visual intelligence systems.
The gap between research detection models and production surveillance systems has never been closer. YOLO26 simplifies it by removing complexity. For engineers building the next generation of camera intelligence, that simplifies the future deployment.